Aerosol Refractive Index Archive - Documentation
File Naming Convention
Files in this database have the following convention COMPOSITION_NAME/LAB_YEAR.RI where:
-
COMPOSITIONis a description of the composition of the measured sample, (all lower case except if a chemical formula e.g. H2O). If the material is birefringent then the ordinary and extraordinary rays are separated as follows:composition_O_Author_year.ricomposition_E_Author_year.ri
composition_X_Author_year.ricomposition_Y_Author_year.ricomposition_Z_Author_year.ri
NAME/LABis either the name of the first author of the published paper from which the data is taken or the name of the scientist or laboratory that provided the data, (Camel case, i.e. as in 'Person').YEARis the year of publication or data release.
Data Format
Refractive index data is formatted in ASCII and comprises two components:
- A header describing the file. Header lines start with the
#character and defined Keywords, i.e.#Keyword = some text - The data which is formatted into columns which are separated by white space (tabs or spaces)
Notes
Legitimate Keywords are:
FORMATDESCRIPTIONDISTRIBUTEDBYSUBSTANCESAMPLEFORMTEMPERATURECONCENTRATIONREFERENCEDOISOURCECONTACTCOMMENT
The only compulsory Keyword is FORMAT which defines the columns of data. Valid FORMAT components are:
-
WAVLwhich indicates the column contains the spectral location in wavelength (μm) -
WAVNwhich indicates the column contains the spectral location in wavenumbers (cm-1) -
Nwhich indicates the column contains the real part of the refractive index -
DNwhich indicates the column contains the uncertainty in the real part of the refractive index -
Kwhich indicates the column contains the imaginary part of the refractive index (always positive) -
DKwhich indicates the column contains the uncertainty in the real imaginary part of the refractive index
Examples:
#FORMAT = WAVL N DN K DKimplies there are five columns: wavelength, real part, real error, imaginary part, imaginary error#FORMAT = WAVN K DKimplies there are three columns: wavenumber, imaginary part, imaginary error
Each row must contain data for all included columns.
For example, if FORMAT = WAVL N K and K (the imaginary part) goes to zero at some wavelength you cannot stop giving a value for K.
In this case, you would just repeat zeros.
K is generally positive.
There are some cases where K is slightly negative due to measurement noise.
In this cases read_ri forces the value to zero.
As the number of Keyword definitions can vary the length of the number of header lines can vary but must be at least one (to define FORMAT).
To avoid very long lines Keyword definitions can extend over more than one line by using ## as the continuation code. For example:
#COMMENT = This is a very long comment split
## over more than one line
ARIA will compile and read_ri.pro will work if only the FORMAT Keyword is present however you are strongly encouraged to define the DESCRIPTION and REFERENCE Keywords.
Additional keywords can be included but will be ignored in forming ARIA and by read_ri.pro.
In compiling ARIA the fields are passed as HTML so use HTML format commands if you want to include subscripts, Greek characters etc.
The DOI keyword will be used to generate a hyperlink on ARIA/data, so the tag should just consist of the DOI and nothing else (so that the hyperlink works) e.g. #DOI=10.1021/jp992349i.
Directory structure
The ARIA datasets are all organised by category then substance. The substance directories are then organised by sample or property, depending on what is relevant for the data. For example, volcanic ash is organised by volcanic eruption (sample) whereas ice is organised by temperature (property). The data is then finally organised by interpolation if there are interpolated and original data files available.
For example, a typical nitric acid directory path is:
Acids/Nitric/0%_to_19%/0%,_263_K_(Biermann_et_al._2000)/interpolated/HNO30_263_Biermann_2000.ri
Interpolation
Some of the refractive index data has small gaps which limits their usefulness. In these cases, we have interpolated the measurements to provided synthetic data. We have used the Piecewise Cubic Hermite Interpolating Polynomial (PCHIP), which is a shape-preserving piecewise cubic interpolation. The two figures below show the performance of the PCHIP method compared to a more traditional spline approach.
| PCHIP | Spline |
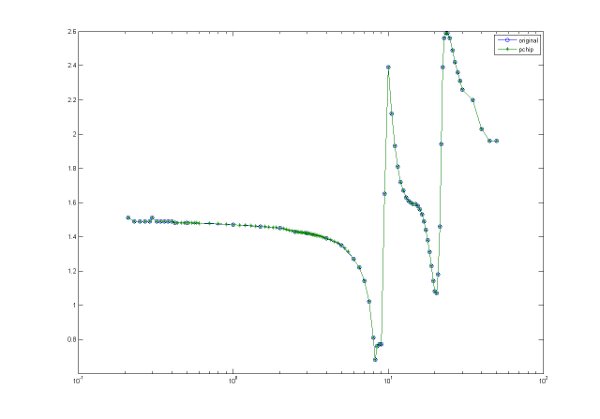
|
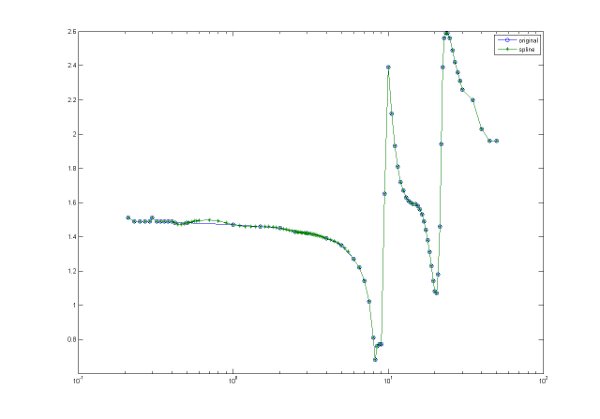
|
| Click on the images for larger versions | |
Files which include synthetic data include a comment to that effect in the file header.
The original files which do not contain any synthetic data have a filename which differs from the standard ARIA filename by the addition of _R to the file prefix.
Read Routines
Routines to read refractive index files:Note that collections of files must be unpacked before they can be read.